
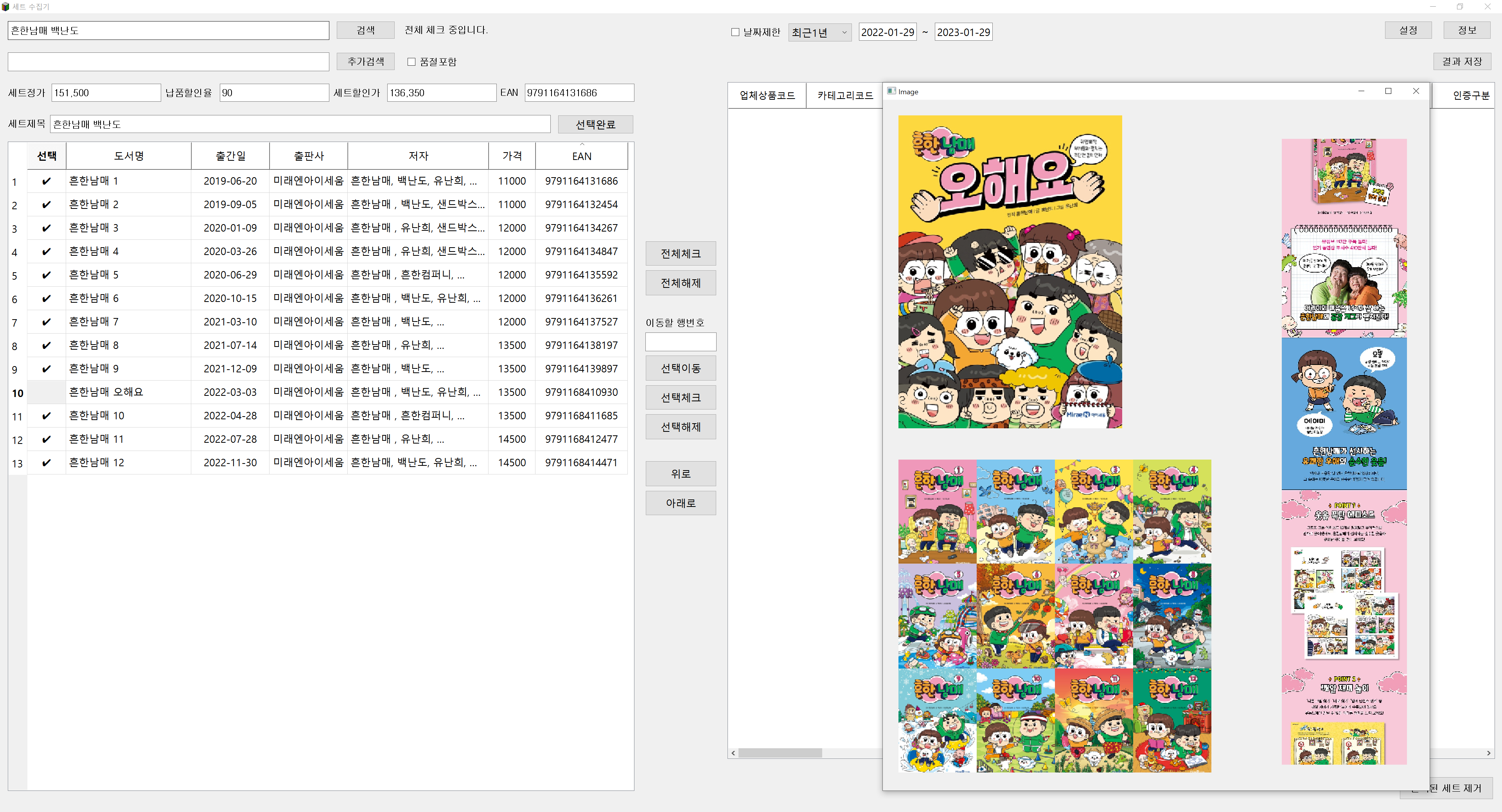
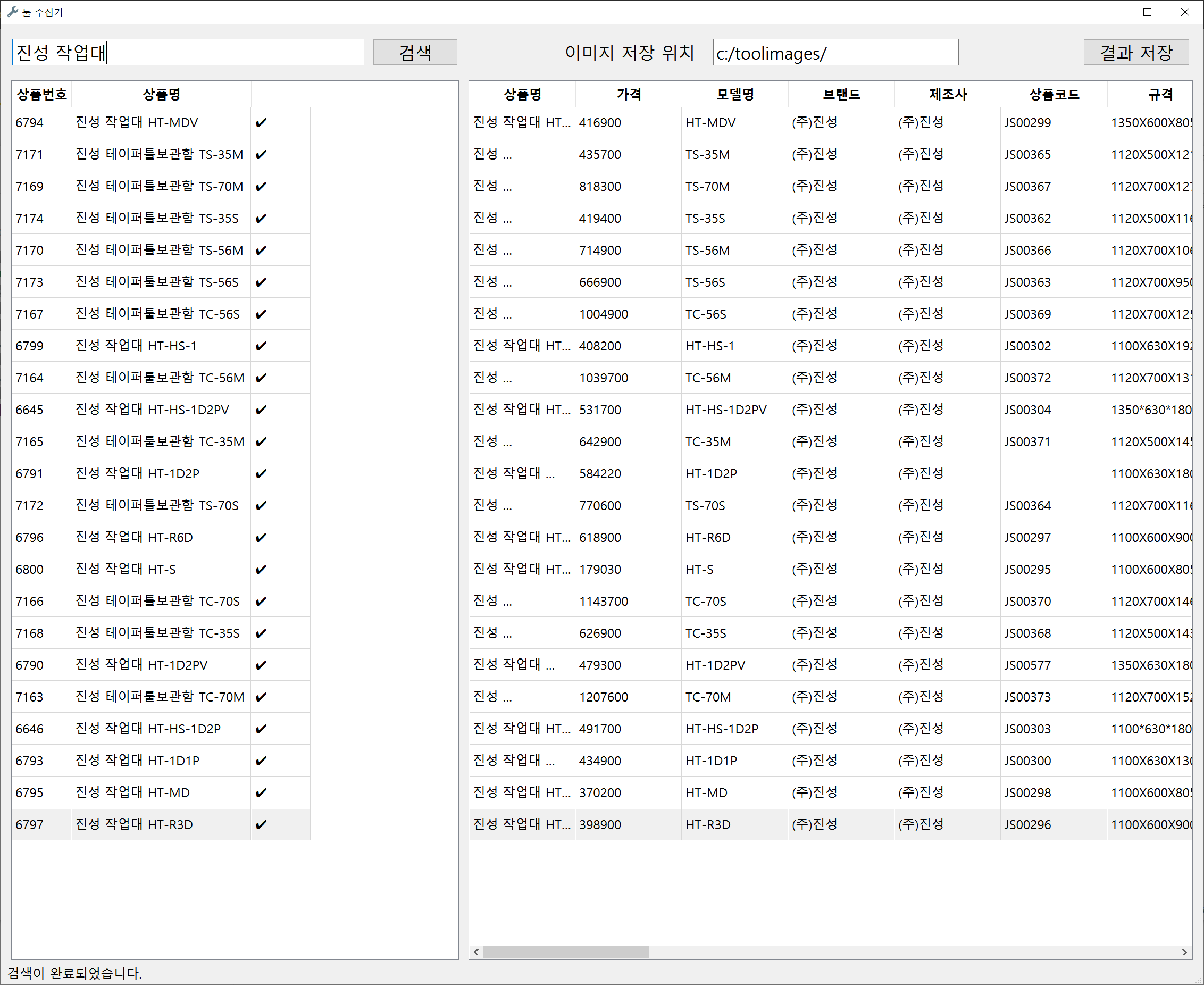
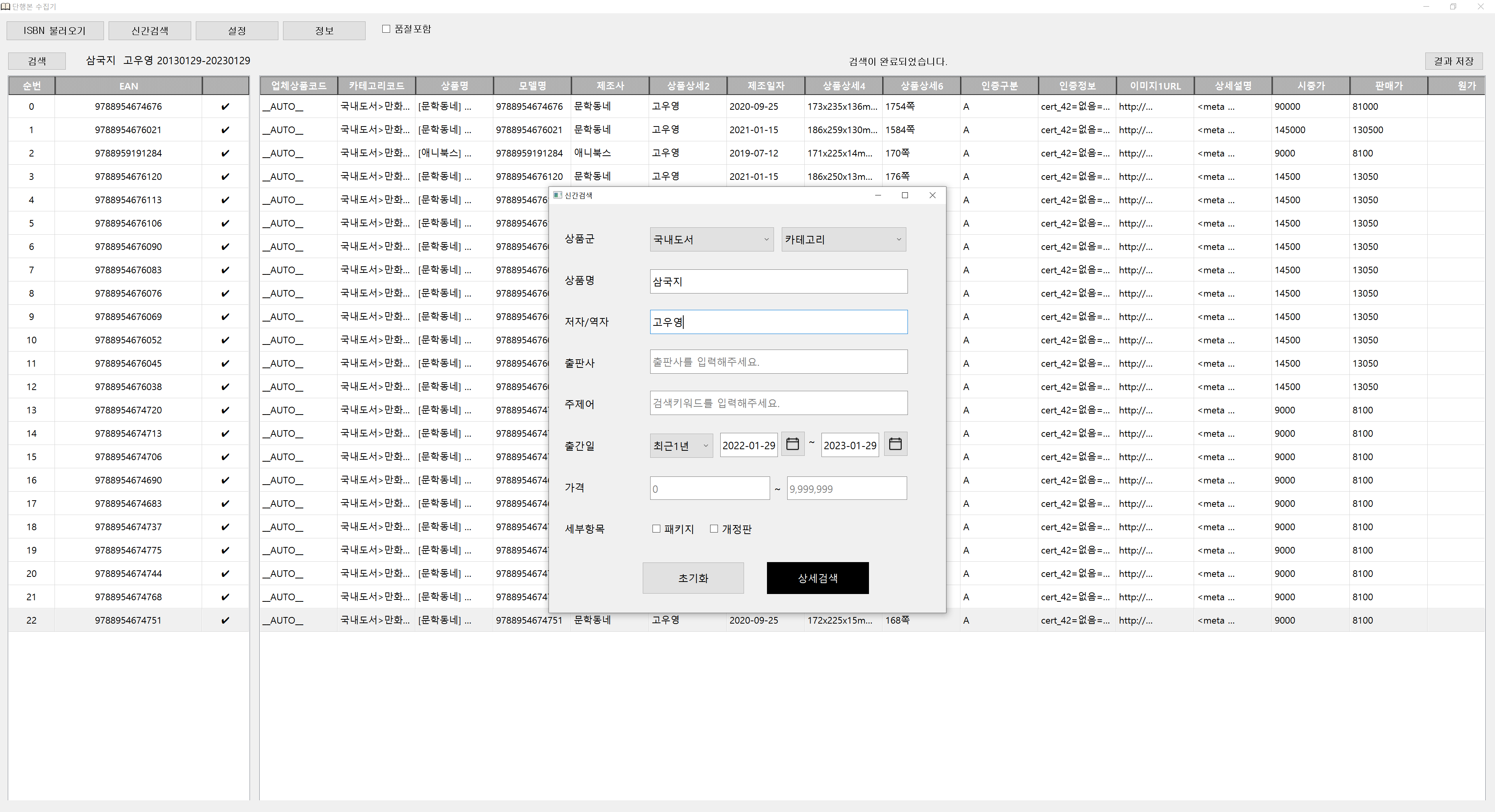
[차원이 다른 데이터 솔루션] 직접 제어 가능한 맞춤형 크롤링 수집기 프로그램 기존 서비스의 한계, 이제 극복하세요!대부분의 크롤링 서비스나 데이터 제공 방식(API/단순 파일 납품)은 다음과 같은 치명적인 문제점을 안고 있습니다.1. 일회성 데이터의 한계: 압축 파일이나 일회성 API로 데이터를 받을 경우, 타겟 사이트에 새로운 정보가 추가되거나 변경되면 그때마다 재구매를 하거나 새로운 요청을 해야 합니다. 데이터가 시간이 지남에 따라 가치를 잃습니다.2. 데이터 활용의 불편함: 수집된 파일(엑셀, 이미지)을 받은 후, 고객이 필요한 정보를 일일이 검색하고 분류해야 하는 비효율적인 수작업이 발생합니다.3. 복잡한 가공의 어려움: 단순 데이터만 제공받을 경우, 이미지를 변형하거나 복잡한 통계 로직을 적용하는 등의 고난도 가공 작업을 고객이 직접 처리해야 합니다. 저희 솔루션의 혁신: 수집기 프로그램 제공의 장점저희는 단순히 '데이터'를 추출하여 전달하는 데 그치지 않고, 고객님의 비즈니스 환경에 맞춰 직접 제어 가능한 '맞춤형 크롤링 수집기 프로그램' 형태로 제공합니다.1. 실시간/반복 수집 및 업데이트 (데이터 주도권):고객님은 프로그램을 직접 실행하여 원하실 때 언제든지 크롤링을 수행할 수 있습니다. 타겟 사이트에 새로운 정보가 올라오면 즉시 데이터를 업데이트하고 DB에 저장하여 항상 최신 상태의 데이터를 유지합니다.2. 복잡한 현장 가공 처리 기능 내장:이미지를 원하는 크기나 비율로 자동 변형/조합하는 기능, 추출된 수치를 기반으로 복잡한 통계나 마진율을 계산하는 등의 고급 데이터 가공 로직을 프로그램 내에 내장하여, 고객님의 추가 작업 없이 최종 가공된 데이터를 제공합니다.3. 원하는 포맷으로 즉시 저장 및 활용:수집된 데이터를 엑셀 파일, PDF 문서는 물론, PostgreSQL, MySQL 등의 데이터베이스(DB)에 즉시 저장하는 기능을 프로그램이 자체적으로 처리하여, 데이터를 바로 업무 시스템에 통합할 수 있습니다. 안정성 보장: IP 블럭을 회피하는 기술VPN/프록시 우회 기능 지원: 대규모 데이터 수집 시 발생하는 IP 블럭 문제를 원천적으로 해결하기 위해, 프로그램 내부에 VPN 및 프록시 네트워크 활용 로직을 통합하여 중단 없는 안정적인 크롤링 작업을 보장합니다.이제 시간 낭비 없이, 고객님의 비즈니스 목표에 맞춘 살아있는 데이터를 직접 소유하고 활용하세요! 맞춤형 크롤링 수집기 프로그램 서비스 제공 절차1단계: 문의 및 상세 요구사항 정의 (Discovery & Estimation)1. 초기 문의 접수: 고객님께서 크롤링을 원하시는 타겟 사이트 주소, 수집할 정보 목록(필드), 수집 목적, 그리고 희망하는 수집량/주기를 상세히 보내주시면 이를 검토합니다.2. 기술 분석 및 상담: 타겟 사이트의 기술적 난이도(로그인 여부, 캡차, IP 블럭 가능성), 필요한 VPN/프록시 적용 여부, 그리고 데이터 가공 로직을 분석하여 개발 가능성과 예상 견적을 안내합니다.3. 최종 범위 및 견적 확정: 협의된 기능과 요구사항을 바탕으로 **프로젝트 범위 정의서(SOW)**를 확정하고 최종 견적을 제시합니다.2단계: 의뢰인 상품 결제 및 개발 착수 (Contract & Setup)1. 결제 진행: 상담 및 견적 안내 후, 고객님께서 크몽을 통해 결제를 완료하시면 프로젝트가 공식적으로 시작됩니다.2. 프로젝트 착수 및 DB/포맷 확정: 개발 시작과 동시에 최종 출력 포맷 (DB 스키마, Excel 헤더 등)을 확정하고, 필요한 경우 고객님의 DB 연동 정보를 확보합니다.3. 중요 공지 (취소 불가능): 결제 완료 후, 개발이 즉시 착수되기 때문에 단순 변심에 의한 취소 및 환불은 불가능합니다. (단, 개발 불가 판정 시 환불 가능)3단계: 개발 및 안정화 (Development & Stabilization)1. 크롤링 모듈 및 가공 로직 개발: 타겟 사이트에 맞춰 데이터 추출 모듈을 개발하고, 이미지 변형, 계산식 적용 등 고객 맞춤형 데이터 가공 로직을 프로그램 내에 구현합니다.2. IP 우회 및 안정성 테스트: 프로그램에 VPN/프록시 우회 기능을 통합하고, 대량 수집 환경에서 IP 블럭 없이 안정적으로 작동하는지 집중적으로 테스트합니다.3. 데이터 저장 모듈 개발: 수집된 데이터가 고객님이 원하는 포맷(DB, Excel, 문서 등)으로 정확하게 변환 및 저장되는 모듈을 개발합니다.4단계: 의뢰인 베타 검수 및 수정 (Client Review & Rework)1. 베타 버전 제공: 기능이 모두 구현된 베타 버전 수집기 프로그램을 고객님께 제공하여 실제 데이터 수집을 요청합니다.2. 의뢰인 검수 및 피드백: 고객님께서는 수집된 데이터의 정확성, 가공 로직의 일치 여부, 그리고 프로그램 사용 편의성을 집중적으로 검토하고 피드백을 전달합니다.3. 버그 수정 및 보완: 전달받은 피드백을 바탕으로 프로그램의 오류를 수정하고 안정성을 최종적으로 확보합니다. (최초 SOW 범위 내에서의 수정은 무상 진행)5단계: 최종 납품 및 서비스 종료 (Final Delivery & Closeout)1. 최종 프로그램 납품: 모든 검수가 완료되면, 고객님께서 바로 사용할 수 있는 최종 실행 파일(EXE) 및 사용 매뉴얼을 전달합니다.2. 서비스 제공 종료: 고객님의 최종 검수 확인 및 크몽 내 '작업 완료' 승인과 함께 서비스 제공이 종료됩니다.3. 사후 지원: 납품 후 [명시된 무상 기간, 예: 30일] 동안 발생하는 프로그램 오류에 대해 무상으로 지원하며, 이후 유상 유지보수 계약을 협의할 수 있습니다. 맞춤형 크롤링 수집기 프로그램 개발 의뢰인 필수 준비사항I. 타겟 사이트 및 데이터 정의 (가장 중요)1. 크롤링 대상 사이트 주소 (URL):데이터를 추출하고자 하는 정확한 웹페이지 URL (예: 검색 결과 페이지, 상세 상품 페이지 등)을 제공해 주세요.2. 수집 목적 및 필요 항목:크롤링을 통해 궁극적으로 달성하려는 목적 (예: 가격 비교, 시장 트렌드 분석, 경쟁사 상품 등록 현황 파악 등)을 명시해주세요.수집해야 할 모든 정보 항목 (필드명)을 구체적으로 나열해주세요. (예: 상품명, 현재 가격, 등록일자, 판매자 ID, 리뷰 평점, 이미지 URL, 재고 상태 등)3. 로그인/접근 필요 여부:해당 사이트가 크롤링 시 로그인이 필요한지 여부를 반드시 알려주세요. (필요 시, 테스트용 임시 계정 정보 제공이 필요합니다.)4. 수집량 및 주기:총 예상 수집 데이터 건수 (예: 10만 건)와 데이터 업데이트를 원하는 반복 주기 (예: 매일 1회, 주 3회 등)를 알려주세요.II. 데이터 가공 및 출력 포맷1. 데이터 가공/정제 로직:수집된 데이터를 어떻게 변형/계산/정제해야 하는지 구체적인 규칙을 정의해주세요. (예: 가격에 10% 마진율을 더해 출력, 특정 키워드가 포함된 리뷰는 제외, 이미지 3장을 조합하여 썸네일 생성 등)2. 최종 출력 포맷 및 환경:수집된 데이터를 최종적으로 저장할 원하는 포맷을 명확히 선택해주세요. (DB 저장 [DB 종류 명시], Excel 파일, CSV 파일 등)3. DB 연동 시: 사용할 DB 종류 (MySQL, PostgreSQL 등)와 접속 정보 및 원하는 테이블 스키마를 준비해 주셔야 합니다.III. 특수 사항 및 기술적 제약1. IP 우회/VPN 관련 요청:크롤링 시 IP 블럭 방지용 VPN이 필요한 지 알려주세요. (개발자 측 연동 시 추가 비용 발생 가능)2. 캡차 (CAPTCHA) 존재 여부:사이트에 캡차가 발생하는지, 또는 특정 행동 시 캡차가 나타나는지 여부를 알려주세요. (자동화 난이도에 영향을 줍니다.)3. 이외 특수한 내용:해당 사이트의 특이 사항이나 이미 시도했으나 실패한 경험 등 개발에 영향을 미칠 만한 모든 정보를 상세히 알려주세요.IV. 프로젝트 관리 및 검수1. 소통 및 검수 담당자:개발 진행 중 질문이나 피드백을 주고받을 수 있는 전담 담당자 연락처 및 소통 채널을 알려주세요.2. 검수 데이터 확정:최종 납품 전 데이터 정확성을 검증할 수 있는 샘플 (예: 500건의 수집 결과)을 정의해 주셔야 검수 기준이 명확해집니다.
로딩중...