
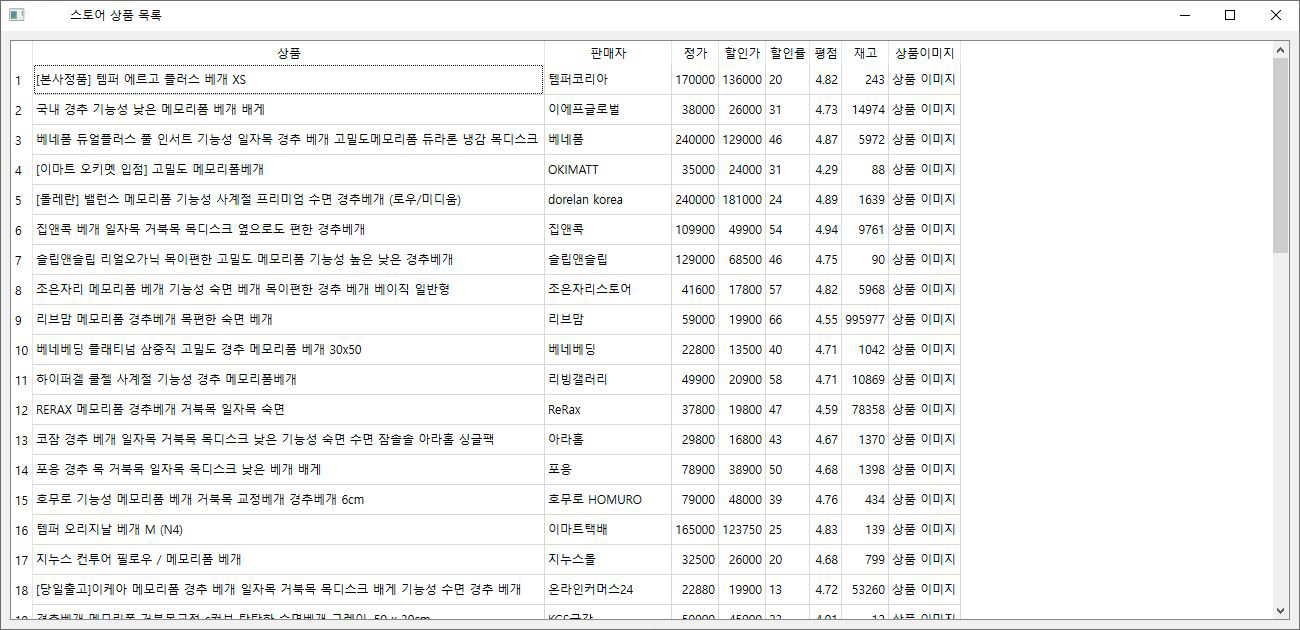
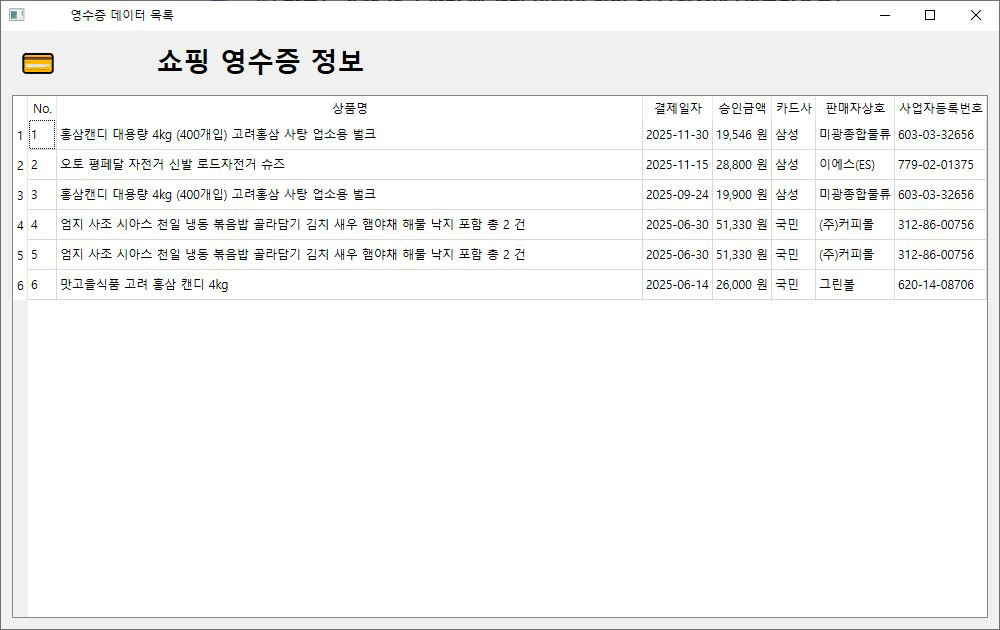
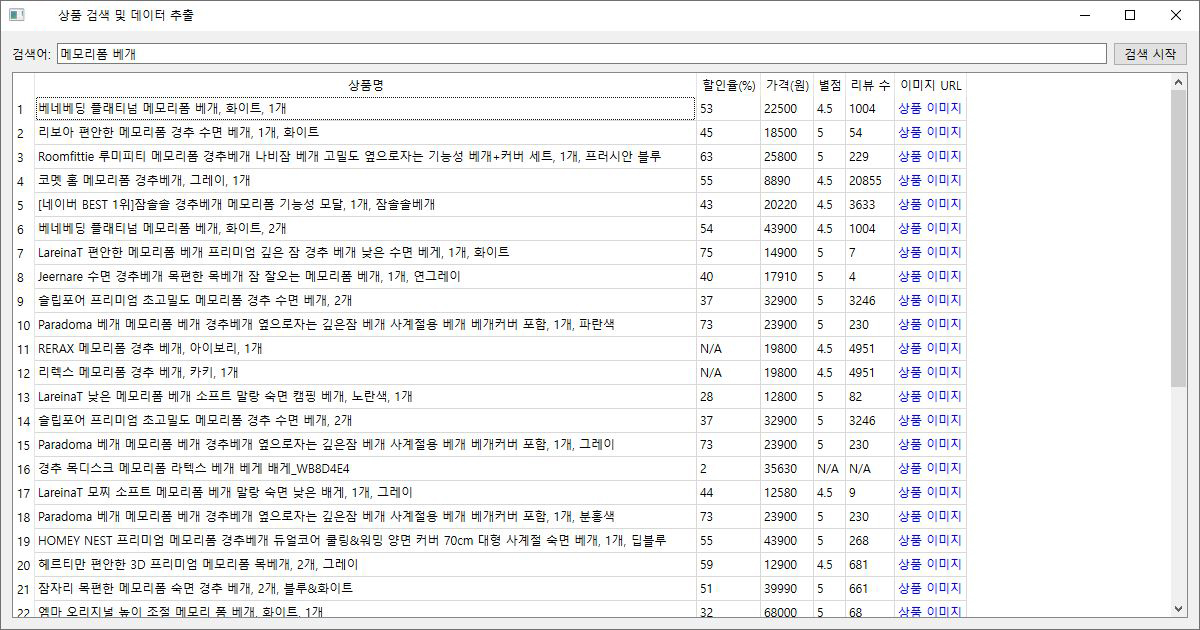
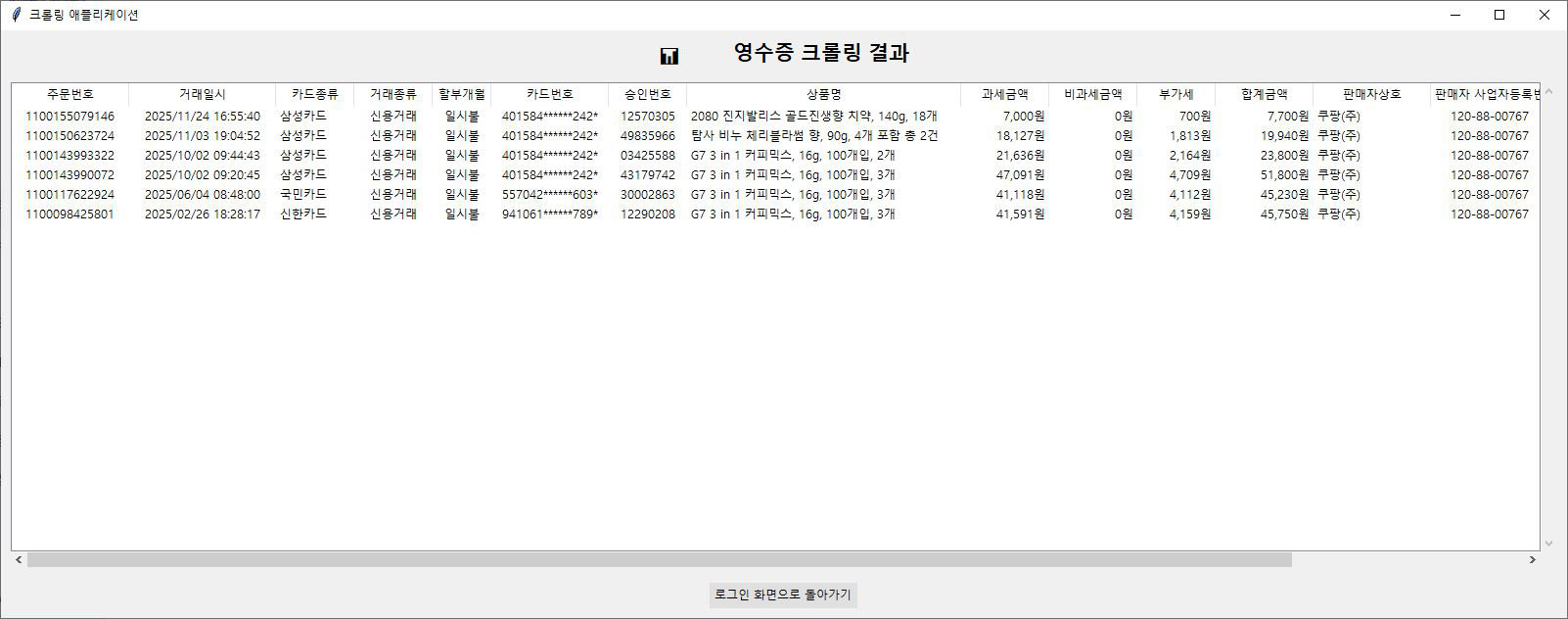
N사/C사 맞춤형 데이터 크롤링 및 가공 서비스[N사/C사 전문] 맞춤형 빅데이터 크롤링 및 원하는 형식(DB/Excel/문서)으로 자동 가공 솔루션"데이터, 이제 손으로 옮기지 마세요. 시간과 노력이 필요한 N사와 C사의 방대한 데이터를 고객님의 비즈니스 목적에 맞게 정밀하게 수집하고, 즉시 활용 가능한 형태로 자동 재가공해 드립니다.단순한 데이터 추출을 넘어, 저희 프로그램은 수집된 정보를 분석, 분류, 정제하여 고객님이 가장 효율적으로 사용할 수 있는 형태로 맞춥니다. 안정적인 크롤링 보장 (IP 블럭 방지)저희 솔루션은 대량 데이터 수집 과정에서 발생하는 IP 차단(블럭) 문제를 원천적으로 방지합니다.VPN 및 프록시 네트워크 활용: 안정적인 VPN 및 프록시 네트워크를 이용하여 IP를 지속적으로 우회하고 변경함으로써, 사이트의 접근 제한 시스템을 회피하고 중단 없는 데이터 수집을 보장합니다. 데이터 활용 및 포맷 지원수집된 데이터는 다음을 포함한 다양한 출력 포맷으로 제공되어 곧바로 업무에 활용할 수 있습니다.• 데이터베이스(DB) 저장: PostgreSQL, MySQL, MongoDB 등 원하는 DB에 즉시 연동 및 저장하여 시스템에 통합합니다.• 보고서/분석 자료: Excel, CSV 파일 형태로 깔끔하게 정리하여 다운로드 및 분석 자료로 활용합니다.• 문서 형태 출력: PDF, Word 등 문서 형태로 변환하여 보고서나 보관 자료로 출력할 수 있습니다.저희 서비스의 차별점• 맞춤형 재가공 로직: 단순 추출을 넘어, 데이터 분류 및 정제 로직을 적용하여 바로 분석 가능한 상태로 제공합니다. (효과: 데이터 분류 및 정제 로직을 적용하여 바로 분석 가능한 상태로 제공합니다.)• 원하는 포맷 지원: DB, Excel, 문서 등 다양한 출력 포맷을 모두 지원하여 추가적인 데이터 변환 작업이 필요 없습니다. (효과: DB, Excel, 문서 등 다양한 출력 포맷을 모두 지원하여 추가적인 데이터 변환 작업이 필요 없습니다.)• 자동화 및 스케줄링: 반복적인 크롤링 작업을 자동화하고 원하는 시간에 맞춰 데이터를 업데이트합니다. (효과: 반복적인 크롤링 작업을 자동화하고 원하는 시간에 맞춰 데이터를 업데이트합니다.) N사/C사 데이터 크롤링 및 가공 서비스 제공 절차1단계: 사전 협의 및 요구사항 분석 (Discovery & Definition)목표 설정 및 상담: 고객님께서 어떤 데이터 (예: 상품명, 가격, 리뷰, 판매자 정보 등)를 N사/C사에서 수집하기를 원하시는지, 그리고 수집 목표량 및 반복 주기를 파악합니다.소스 및 제약사항 검토: 크롤링할 웹페이지 URL 및 데이터 위치를 확정하고, 해당 사이트의 접근 제한 및 보안 정책(IP 블럭, 로그인 필요 여부 등)을 분석합니다.데이터 가공 포맷 확정: 수집된 데이터를 최종적으로 어떤 형태로 받기를 원하시는지 결정합니다. (DB 저장 [PostgreSQL, MySQL 등], Excel/CSV 파일, 또는 문서 출력 등).견적 및 계약: 확정된 요구사항 및 포맷, 예상 개발 기간을 바탕으로 최종 견적을 제시하고 크몽 결제 후 프로젝트를 착수합니다.2단계: 데이터베이스 및 구조 설계 (Structure Design)최종 DB 스키마 설계: 고객님의 비즈니스 목적에 맞게 수집된 데이터를 저장하고 분석할 수 있는 최적화된 데이터베이스 테이블 구조를 설계합니다.데이터 정제 로직 정의: 추출된 원본 데이터(예: 불필요한 HTML 태그, 특수 문자)를 어떻게 분류, 필터링, 정규화할지 구체적인 로직을 정의합니다. (예: 가격 데이터의 문자열 제거, 날짜 형식 통일 등).3단계: 크롤링 모듈 개발 및 안정화 (Development & Stabilization)핵심 크롤링 모듈 개발: 확정된 수집 소스에 맞춰 데이터를 안정적으로 추출하는 파이썬(Python) 기반의 크롤링 모듈을 개발합니다.IP 우회 및 블럭 방지 기능 통합: 대규모 또는 반복적인 크롤링 시 발생하는 IP 차단 문제를 해결하기 위해 VPN 또는 프록시 네트워크 활용 로직을 통합하고 테스트하여 안정성을 확보합니다.데이터 가공 및 변환 모듈 개발: 2단계에서 정의된 로직에 따라 추출된 데이터를 DB 연동, Excel 파일 생성 등 최종 포맷으로 변환하는 모듈을 구현합니다.4단계: 테스트 및 고객 검수 (Testing & Acceptance)내부 통합 테스트: 전체 크롤링 파이프라인(수집 정제 포맷 변환 출력)에 대해 개발자가 데이터 무결성과 시스템 안정성을 집중적으로 테스트합니다.고객 데이터 검수 (PoC): 수집된 샘플 데이터를 고객님께 제공하여, 데이터의 정확성, 포맷, 그리고 원하는 정제 로직이 제대로 적용되었는지 확인받고 피드백을 받습니다.오류 수정 및 최적화: 검수 과정에서 발견된 오류를 수정하고, 크롤링 속도 및 안정성을 최종적으로 최적화합니다.5단계: 최종 납품 및 사후 지원 (Delivery & Support)최종 프로그램/소스 코드 납품: 고객님께서 직접 실행하고 사용할 수 있는 최종 프로그램 파일(EXE/실행 스크립트) 및 요청 시 소스 코드를 납품합니다.사용 매뉴얼 및 교육: 프로그램 실행 방법, 설정 변경 방법, 데이터 추출 및 저장 옵션 사용법 등에 대한 상세 매뉴얼을 제공하고, 간단한 사용법을 교육합니다.무상 유지보수: 최종 납품 후 [명시된 기간, 예: 30일] 동안 발생하는 기능 오류에 대해 무상으로 수정합니다. (단, N사/C사 사이트의 대규모 UI/HTML 구조 변경은 유상 수정 대상이 될 수 있습니다.) N사/C사 데이터 크롤링 및 가공 서비스 의뢰인 준비사항I. 프로젝트 착수 전 필수 정의 사항1. 정확한 데이터 수집 목표 정의:• 수집 대상 URL 확정: 크롤링하려는 N사/C사 웹페이지의 정확한 URL 또는 검색 키워드를 제공해야 합니다. (예: 특정 상품 카테고리 URL, 특정 검색어의 결과 페이지 등)• 필수 추출 항목 확정: 각 페이지에서 반드시 추출되어야 할 데이터 필드를 명확히 정의해주세요. (예: 상품명, 현재 가격, 배송비, 평점, 리뷰 본문, 판매자ID, 등록일 등)• 수집량 및 주기: 필요한 최대 수집 데이터 건수와 데이터를 반복적으로 업데이트해야 할 주기 (예: 매일 새벽 3시, 주 1회 등)를 알려주셔야 합니다.2. 데이터베이스(DB) 및 출력 포맷 결정:• 최종 출력 포맷 결정: 수집된 데이터를 최종적으로 DB 저장 (DB 종류 명시: MySQL, PostgreSQL 등), Excel/CSV 저장, 또는 문서 형태로 출력 중 무엇을 원하시는지 확정해야 합니다.• DB 연동 정보 준비 (필요시): 만약 고객님의 기존 시스템 DB에 직접 저장해야 한다면, **DB 접속 정보(호스트, 계정, 비밀번호)**와 **테이블 구조(스키마)**를 미리 준비하여 공유해야 합니다.3. 데이터 가공 및 정제 로직 정의:• 정제 규칙 명시: 수집된 데이터 중 불필요한 내용(예: HTML 태그, 특정 광고 문구)을 제거하거나 가공하는 규칙을 정의해주세요.• 데이터 분류 기준: 최종 출력 시 데이터를 특정 기준에 따라 분류, 필터링, 또는 계산해야 한다면 그 로직을 상세히 설명해주셔야 합니다. (예: '평점 4.5 이상'인 데이터만 추출, 가격이 1만원 이상인 상품만 '프리미엄'으로 분류).II. 개발 진행 시 기술 지원 사항API 및 시스템 접근 권한 (필요시):외부 API나 고객님의 내부 시스템과 연동이 필요하다면, 개발자가 테스트 및 연동 작업을 진행할 수 있도록 접근 권한, API 키, 또는 문서를 제공해야 합니다.III. 테스트 및 최종 검수 준비1. 검수용 샘플 데이터 확정:최종 프로그램 납품 전 검수 기준으로 사용할 데이터 샘플 (예: 500건)을 정해주세요. 이 샘플 데이터의 추출 정확성이 최종 승인 기준이 됩니다.2. 피드백 및 소통 전담:개발 기간 중 기능 및 데이터 정확도에 대한 질문이나 검수 피드백을 신속하게 주고받을 수 있는 담당자를 지정해야 합니다.
로딩중...